The rapid advancements in Large Language Models (LLMs) in Cyber Security Outsourcing Services have opened up new possibilities across various applications, from content generation to intelligent chatbots. However, ensuring the quality, reliability, and performance of these models is a significant challenge. Without robust evaluation metrics, it's difficult to:
Assess Model Performance: Determine if an LLM is meeting its intended objectives and performing as expected in real-world scenarios.
Compare Different Models/Versions: Objectively evaluate and choose the best LLM among several options or track improvements across different iterations of the same model.
Identify and Mitigate Biases/Errors: Pinpoint areas where the LLM might be generating inaccurate, biased, or harmful content, and take corrective actions.
Ensure Consistency and Quality: Maintain a high standard of output quality, especially when LLMs are deployed in critical applications.
Optimize Model Development: Guide the development process by providing clear feedback on what needs improvement, leading to more efficient fine-tuning and training.
LLM Evaluation Metrics
What is a Metric?
In the context of LLM evaluation, a "metric" is a quantifiable measure used to assess specific aspects of an LLM's output. These measures allow for objective comparison and performance tracking.
How a Metric Works:
Metrics typically involve comparing the LLM's generated output against a reference or ground truth. The comparison can be based on various criteria, such as:
Lexical Overlap: Measuring the common words or phrases between the generated text and reference text (e.g., BLEU, ROUGE).
Semantic Similarity: Assessing the meaning correspondence between the generated text and reference text, even if the exact words differ (e.g., BERTScore).
Factuality: Checking if the generated information is accurate and supported by evidence.
Coherence and Fluency: Evaluating how well the generated text flows and makes sense.
Safety and Bias: Identifying instances of toxic, biased, or harmful content.
Task-Specific Performance: Measuring how well the LLM performs on a particular task (e.g., accuracy for question answering, slot filling for intent recognition).
Metrics often produce a numerical score, where a higher or lower score (depending on the metric) indicates better performance.
LLM Evaluation Metrics in Promptfoo Framework
The Promptfoo LLM Testing framework offers a versatile and comprehensive suite of evaluation metrics, known as "assertions," to systematically test and validate the performance of Large Language Models (LLMs). These metrics range from simple, rule-based checks to sophisticated model-graded evaluations, allowing for a multi-faceted analysis of your prompts and models. The core of this system is configured within the promptfooconfig.yaml file, where you define your test cases and the assertions to run against them.
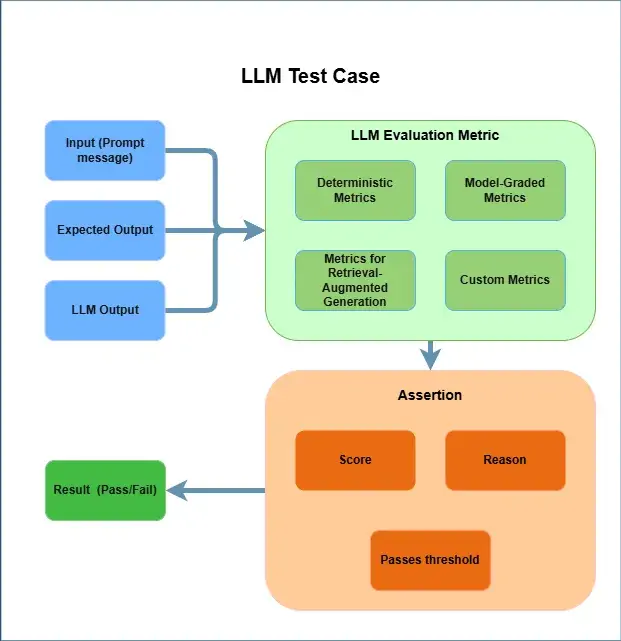
Deterministic Metrics: Rule-Based Validation
These are foundational, objective checks that validate the structure and content of an LLM's output against predefined rules. They are fast, reliable, and ideal for ensuring outputs meet specific formatting and content requirements.
Common Deterministic Metrics:
Content and Structure:
contains, icontains (case-insensitive): Checks if the output includes a specific substring.
starts-with, equals: Verifies the beginning or the entirety of the output.
regex: Matches the output against a regular expression.
is-json, is-sql, is-xml: Validates if the output is a well-formed JSON, SQL, or XML structure.
Semantic and Lexical Similarity:
rouge-n, bleu: Calculates classic NLP scores for content overlap, useful for summarization and translation tasks.
levenshtein: Measures the edit distance between the output and a target string.
similar: Uses embeddings to check for semantic similarity between the output and a reference text, which is more powerful than simple keyword matching.
Performance and Cost:
latency: Ensures the response time is below a certain threshold.
cost: Tracks the inference cost and asserts it stays within a budget.
Safety and Refusal:
is-refusal: Checks if the model refuses to answer a prompt.
Example promptfooconfig.yaml with Deterministic Metrics:
prompts:
- ‘You are a helpful travel assistant. Suggest three activities in {{city}}.’
providers:
- openai:gpt-4o-mini
tests:
- vars:
city: Paris
assert:
- type: contains
value: 'Eiffel Tower'
- type: is-json
- type: latency
threshold: 2000 # must respond within 2 seconds
Model-Graded Metrics: AI-Powered Evaluation
For more nuanced aspects like quality, tone, and factuality, Promptfoo leverages model-graded metrics. These use another LLM (the "grader") to evaluate the output based on a given rubric or criteria.
Key Model-Graded Metrics:
llm-rubric: This is a highly flexible metric where you provide a natural language rubric for the grader LLM to follow. It's excellent for checking for specific styles or complex instructions.
g-eval: Based on the G-Eval framework, this metric uses chain-of-thought prompting to evaluate outputs against custom criteria, providing a score between 0 and 1.
factuality: Compares the generated output against a reference answer to check for factual consistency.
model-graded-closedqa: Determines if the output meets a specific, closed-ended requirement.
select-best: A comparative metric where you provide multiple outputs for the same test case and instruct the grader to choose the best one based on a given criterion (e.g., "choose the most creative response").
Example promptfooconfig.yaml with Model-Graded Metrics:
prompts:
- ‘Write a professional but friendly email responding to a client complaint about a late shipment.’
providers:
- openai:gpt-4o
defaultTest:
options:
provider: openai:gpt-4o-mini # Using a smaller model as the grader
tests:
- vars:
client_name: 'Jane Doe'
product: 'SuperWidget'
assert:
- type: llm-rubric
value: 'The email should be apologetic, professional, and offer a solution.'
- type: g-eval
value:
- 'Maintains a professional tone'
- 'Expresses empathy for the client's frustration'
threshold: 0.8
Metrics for Retrieval-Augmented Generation (RAG)
Promptfoo provides a specialized set of metrics to evaluate the distinct components of a RAG pipeline, ensuring both the retrieval and generation steps are performing optimally.
context-relevance: Measures if the retrieved context is relevant to the user's query.
context-recall: Assesses whether the retrieved context contains the necessary information to answer the query, based on a ground-truth reference.
context-faithfulness: Checks if the LLM's generated answer is factually supported by the provided context, helping to identify hallucinations.
answer-relevance: Ensures that the final generated answer is relevant to the original user query.
Custom Metrics: Ultimate Flexibility
For highly specific or proprietary evaluation needs, Promptfoo allows you to define your own metrics using JavaScript or Python. This provides limitless possibilities for validation.
JavaScript Assertions: You can write a JavaScript function that takes the output and a context object as input and returns a boolean, a score, or a detailed GradingResult object.
Python Assertions: Similarly, you can define a Python function to perform custom validation logic.
Example promptfooconfig.yaml with a Custom Python Metric:
prompts:
- ‘Generate a 4-digit security code.’
providers:
- openai:gpt-3.5-turbo
tests:
- assert:
- type: python
value: |
def check_code(output):
return output.isdigit() and len(output) == 4
assert check_code(output)
By combining these different types of metrics, Promptfoo enables a robust and layered approach to LLM evaluation, ensuring your applications are not only functional but also reliable, accurate, and safe.
Assertions and Metrics in Promptfoo LLM Testing
In Promptfoo, you define pass/fail criteria for your LLM outputs using assertions. These are checks you specify in your promptfooconfig.yaml file that automatically validate each test result, telling you instantly whether a response meets your quality standards.
Deterministic Assertions
These assertions use clear, objective rules to establish a pass/fail outcome. The criteria are binary—the output either meets the rule or it doesn't.
How it works: You define a specific rule, and Promptfoo checks if the output adheres to it.
Examples of Pass/Fail Criteria:
type: is-json passes if the output is a valid JSON object and fails otherwise.
type: contains, value: 'Thank you for your inquiry' passes only if that exact phrase is present.
type: regex, value: '^\d600$' passes if the output is exactly five digits and fails for any other format.
Model-Graded Assertions
For subjective qualities like tone or relevance, the pass/fail criterion is set using a threshold.
How it works: You provide a rubric, and a separate "grader" LLM scores the output, usually on a scale of 0 to 1. The test passes only if the score meets or exceeds the threshold you set.
Example of Pass/Fail Criteria:
You might use type: llm-rubric, value: 'The tone is helpful and empathetic', and set a threshold: 0.8.
The assertion passes if the grader LLM scores the output 0.8 or higher. It fails if the score is 0.79 or lower.
Custom Assertions
When you write your validation logic in Python or JavaScript, you define the pass/fail conditions directly in your code.
How it works: The outcome depends entirely on your custom logic.
Example of Pass/Fail Criteria:
In a Python assertion, the test passes if your function runs without raising an AssertionError and fails if it does.
In JavaScript, the test passes if your function returns true and fails if it returns false.
Here are suitable metrics from the Promptfoo FW for testing a Generated MQL queries model, a Generated JSON model, and a Chatbot model:
Suitable metrics for Cybersecurity outsourcing LLM Testing service at TMA Solution
Generated MQL Queries Model
The primary goal for an MQL (Monitoring Query Language) queries model is to generate syntactically correct and semantically accurate queries that achieve the desired outcome.
Deterministic Metrics (Assertions):
is-sql: While MQL is not SQL, Promptfoo's is-sql assertion can be adapted or serves as an example of a similar type of structural validation. For MQL, you would likely need a Custom Assertion (JavaScript or Python) that checks for:
Syntactic Correctness: A custom function that parses the MQL output and verifies it adheres to the MQL grammar rules. This is crucial as a malformed query will fail to execute.
Specific MQL Keywords/Structure: Assertions to ensure the presence of expected MQL clauses (e.g., FROM, WHERE, SELECT, specific MQL functions) relevant to the query's intent.
regex: To validate specific patterns within the MQL query, such as expected table names, column formats, or argument structures for MQL functions.
contains / icontains: To ensure specific, crucial elements or security-related clauses are present or absent in the generated query.
latency: To ensure the query generation is within acceptable time limits.
cost: To monitor the token usage and cost for generating the MQL query.
Model-Graded Metrics:
llm-rubric: Can be used to evaluate the semantic accuracy or efficiency of the generated MQL query. For example, "Does the generated MQL query accurately retrieve the intended data?" or "Is the MQL query optimized for performance?".
g-eval: To assess the correctness and efficiency of the MQL query based on a specific context or desired outcome. For example, criteria could be "The query correctly filters by date range" or "The query selects only necessary fields."
Custom Metrics (Highly Recommended):
Execution Validation (Python/JavaScript): The most robust metric would be a custom assertion that attempts to execute the generated MQL query against a dummy or test database and asserts that:
The query executes without errors.
The results returned by the query match the expected output for the given prompt (e.g., specific data points, number of rows).
Schema Conformance: A custom metric to ensure the MQL query references valid tables and columns according to a predefined schema.
Generated JSON Model
The primary goal is to generate JSON that is well-formed, valid according to a schema, and contains the correct data.
Deterministic Metrics (Assertions):
is-json: This is a fundamental and essential assertion to ensure the output is valid JSON.
Custom Assertion (JavaScript or Python) for JSON Schema Validation: Promptfoo can be extended to include a custom assertion that checks if the generated JSON conforms to a predefined JSON schema. This is critical for data consistency and interoperability.
contains / icontains: To check for the presence of specific keys or values within the JSON output.
regex: To validate the format of specific string values within the JSON (e.g., email addresses, UUIDs, dates).
latency: To ensure the JSON generation is performant.
Model-Graded Metrics:
llm-rubric: To evaluate the "completeness" or "accuracy" of the JSON data based on natural language descriptions. For example, "Does the JSON include all required user profile fields?" or "Are the values in the JSON factually correct based on the prompt?"
Custom Metrics (Recommended):
Data Validation: A custom JavaScript or Python function to perform deeper validation of the JSON content, beyond just schema validation. This could include:
Cross-field dependencies (e.g., if field A has value X, then field B must have value Y).
Value ranges or enumerations.
Logical consistency of data.
Chatbot Knowledge Base (KB) Model
Evaluating a chatbot requires assessing its ability to provide relevant, helpful, coherent, and safe responses, often in a conversational context.
Deterministic Metrics (Assertions):
contains / icontains: To ensure the chatbot's response includes or avoids specific keywords or phrases (e.g., "contains 'client service'", "does not contain 'offensive language'").
regex: For checking patterns in the response, such as dates, phone numbers, or specific formatting for answers.
is-refusal: To check if the model appropriately refuses to answer out-of-scope or unsafe prompts.
latency: To ensure the chatbot responds within an acceptable time frame for user experience.
cost: To monitor the inference cost per turn.
Model-Graded Metrics (Highly Recommended):
llm-rubric: The most flexible for subjective chatbot qualities. You can define rubrics for:
Relevance: "Does the response directly answer the user's question?"
Helpfulness: "Is the response useful and actionable?"
Tone: "Is the tone appropriate (e.g., friendly, professional, empathetic)?"
Coherence/Fluency: "Is the response easy to understand and grammatically correct?"
Factuality: "Is the information provided factually accurate?" (Especially important if the chatbot accesses external knowledge).
Safety/Bias: "Does the response avoid harmful, biased, or toxic content?"
Conciseness: "Is the response concise and to the point without unnecessary verbosity?"
g-eval: Similar to llm-rubric, but often used for a more structured, score-based evaluation against multiple criteria.
factuality: If the chatbot is expected to provide factual information, this metric can compare its output to a known ground truth.
model-graded-closedqa: If the chatbot is designed to provide specific, closed-ended answers to certain types of questions.
select-best: Useful for A/B testing different chatbot prompts or models, where a grader LLM selects the preferred response based on defined criteria (e.g., "Which response is more engaging?").
Table Of Content
Start your project today!
Share:



